
企業の承認なしに従業員が AI ツールを利用する「シャドー AI」。[前回の記事](https://narupaso.com/testarea/blog-detail.html?id=e3vkxoh5e)でも解説した通り、業務効率化への期待の裏で、機密情報の漏洩リスクに頭を悩ませる経営者や IT 担当者も多いのではないでしょうか。
しかし、AI 利用を単純に「禁止」するだけでは、現場の生産性を下げ、イノベーションの芽を摘んでしまいかねません。
もし、外部のサーバーに一切頼らず、自社の管理下で安全に使える AI 環境を構築できるとしたら?
本記事では、`gpt-oss`に代表されるオープンソースの大規模言語モデル(LLM)を活用し、情報漏洩リスクをゼロにする「ローカル AI」という新しい選択肢を提案します。これは、シャドー AI 問題に対する「守り」の策であると同時に、企業の競争力を高める「攻め」の DX 戦略にもなり得るのです。
中小企業が抱える AI 導入のジレンマ
多くの企業、特に中小企業にとって、AI 導入は大きなジレンマを抱えています。
一方には、ChatGPT に代表されるクラウドベースの AI サービスがあります。これらは導入が手軽で非常に高性能ですが、利用量に応じた API 料金という継続的なコストが発生します。さらに重要なのは、社内の機密情報や顧客データを外部のサーバーに送信することへのセキュリティ不安が常に付きまとう点です。
もう一方には、自社でサーバーを構築・運用する本格的なオンプレミス環境があります。こちらはセキュリティ面では理想的ですが、高価な AI サーバーの導入費用、運用・保守を行う専門人材の確保など、コスト面でもリソース面でも、多くの中小企業にとっては現実的な選択肢とは言えませんでした。
これまでは、便利だがリスクのある「クラウド」か、安全だが高すぎる「オンプレミス」か、この究極の選択を迫られていたのです。
新しい選択肢:「手元の AI を『相棒』にする」という発想
この二者択一の状況に、第三の道を示すのが「ローカル AI」です。
数年前まで、「ローカル環境で動く AI」といえば、高価なグラフィックボードを搭載した特別な PC で画像を生成するような、一部の専門家やマニアックな趣味の世界というイメージが強かったかもしれません。しかし今、私たちがビジネスで本当に求めている「思考する AI」、つまり大規模言語モデル(LLM)を、もっと身近な環境で、まるで「相棒」のように活用する時代が訪れようとしています。
かく言う私も、来るべき日に備え、現実的な選択肢を模索していました。Windows 10 のサポート終了を機に新しい PC を準備する際、将来的に高性能なグラフィックボード(GPU)を手軽に増設できる「OcuLink」という規格に対応したモデルを選びました。しかし、LLM を快適に動かす目安とされる VRAM 16GB クラスの GPU は、今なお十数万円と高価です。そのため、「本格的なローカル AI はまだ先の話。まずは LLM の仕組みの勉強から始めよう」というのが、当初の正直な気持ちでした。
高価な GPU への投資に二の足を踏んでしまうこの感覚は、多くの中小企業の経営者や担当者の方々と共通するのではないでしょうか。
その主役となるか?「gpt-oss」とオープンソース LLM の現状
高価な GPU への投資をためらい、ローカル AI の導入を「まだ先の話」だと感じていた私や、多くの中小企業にとって、まさにゲームチェンジャーと呼べる存在が登場しました。
その筆頭が、今回注目する`gpt-oss`です。
このプロジェクトが画期的だったのは、これまでローカルで LLM を動かす際の常識だった「高性能な GPU が必須」という前提を覆し、CPU だけで十分に動作する点にあります。もちろん、処理速度の面では GPU に劣りますが、「まずは試してみる」という第一歩を踏み出す上での最大の障壁であった、数十万円規模のハードウェア投資が不要になったのです。
この変化は、ちょうど多くの企業が Windows 10 のサポート終了に伴う PC の入れ替えを検討しているタイミングと重なります。一般に「AI パソコン」として販売されている高価なモデルでなくとも、近年の標準的なビジネス PC であれば、十分にローカル AI を試せる環境が整ったと言えるでしょう。
さらに、この流れを加速させているのが、`Ollama`や`LM Studio`といったツールの存在です。これらは、様々なオープンソース LLM を、まるでアプリをインストールするような手軽さで自分の PC に導入し、動かすことを可能にします。複雑なコマンド入力や環境構築は必要ありません。
つまり、「高価な GPU がなくても動くモデル (`gpt-oss`など)」と、「それを簡単に動かすためのツール (`Ollama`など)」の両輪が揃ったことで、ローカル AI は専門家やマニアのものではなく、私たちビジネスパーソンにとって、極めて身近で現実的な選択肢へと変わったのです。
企業がローカル AI を導入する 4 つのメリット
`gpt-oss`のようなオープンソース LLM を活用したローカル AI 環境は、これまで中小企業が抱えていたジレンマを解消し、多くのメリットをもたらします。特に「セキュリティ」と「コスト」の面で、クラウドサービスとは一線を画す大きな利点があります。
① 鉄壁のセキュリティと完全なガバナンス
ローカル AI 最大のメリットは、何と言っても鉄壁のセキュリティです。AI とのやり取りはすべて社内の PC やサーバー内で完結するため、機密情報や顧客データ、開発中のソースコードなどが外部のサーバーに送信されることは一切ありません。情報漏洩のリスクを原理的にゼロにできるのです。
これは、前回の記事で解説した「シャドー AI」問題に対する最も直接的で効果的な解決策となります。従業員の「AI を業務に活用したい」という前向きな意欲を禁止するのではなく、企業が管理する安全な環境を提供することで、そのニーズに応えることができます。さらに、誰が、いつ、どのような目的で AI を利用したかを完全に把握できるため、AI 利用における完全なガバナンスを確立することも可能です。
② コスト管理の容易さ
クラウドベースの AI サービスで懸念されるのが、利用量に応じて変動する API 料金です。例えば、個人が趣味のプログラミングやブログ執筆で頻繁に利用した場合でも月に 3,000 円~ 5,000 円程度、企業が業務システムに組み込んで本格的に活用するとなると、その利用量によっては月に 15,000 円~ 30,000 円、あるいはそれ以上のコストになる可能性も十分に考えられます。特に大規模なデータ処理や頻繁な利用が発生すると、コストが想定外に膨れ上がるリスクがあるのです。
ローカル AI であれば、一度ハードウェア環境を構築してしまえば、こうした月々の API 利用料は発生しません。初期投資は必要ですが、中長期的に見れば、ランニングコストを大幅に抑制し、予算管理を容易にします。
③ 高度なカスタマイズ性
オープンソースの LLM は、自社のデータを使って「ファインチューニング」と呼ばれる追加学習を行うことができます。 「ファインチューニング」という言葉は少し難しく聞こえるかもしれませんが、これは「AI の新入社員研修」のようなものだとイメージしてください。
汎用的な LLM は、いわば「一般教養は完璧だが、まだ自社のことは何も知らない新入社員」です。ここに、外部には決して出せない「社内マニュアル」「過去の議事録」「顧客との応対履歴」「製品の技術仕様書」といった独自のナレッジを"教材"として与え、追加学習させる。これがファインチューニングです。 この研修を経ることで、AI は以下のように変化します。
研修前:「製品 ABC のトラブル対応は?」→「一般的なトラブル対応として…」という一般論しか返せなかった。
研修後:「製品 ABC のトラブル対応は?」→「過去の事例によれば、エラーコード E-503 が出た場合は基盤 XX のリセットが有効です」
と、社内のナレッジに基づいた具体的な回答ができるようになる。
このように、自社の業務に特化した「お抱えの専門家」を育成できることこそ、ローカル AI が持つ強力な競争優位性なのです。
④ オフラインでの利用可能性
ローカル AI は、インターネット接続が不安定な環境や、セキュリティポリシー上外部ネットワークから切り離された環境でも利用できます。災害時や移動中など、あらゆる状況で安定して AI の能力を活用できる点も、ビジネス継続性の観点から大きなメリットと言えるでし ょう。
gpt-oss の頭脳:モデルサイズ 20B と 120B は何が違うのか?
ここまで `gpt-oss` の手軽さについて解説してきましたが、ここで少し技術的な側面に触れておきましょう。`gpt-oss` には、性能や動作要件が異なる複数の「モデルサイズ」が存在します。 現在、主に解説しているのは「20B」モデルです。この「B」は "Billion"(10 億)の略で、AI の賢さを決める「パラメータ」という数値の数を表します。つまり、20B は 200 億パラメータを持つモデルということです。このモデルの最大の利点は、前述の通り CPU でも動作するほどの軽量さでありながら、多くの業務をこなせる十分な性能を持っている点です。この記事で紹介している「手軽に始めるローカル AI」の主役は、まさにこの 20B モデルです。
同時に、さらに高性能な「120B」(1200 億パラメータ)モデルも発表されており、大きな注目を集めています。
20B モデル(200 億):
- 特徴: CPU でも動作する軽量さ。ローカル AI の入門に最適。
- 用途: 文章作成、要約、アイデア出しなど、一般的なタスクに幅広く対応。
- 立ち位置: まずは試してみるための「現実的な選択肢」。
120B モデル(1200 億):
- 特徴: 非常に高い性能を持ち、快適な速度で動かすには高性能な GPU が推奨されます。技術的には CPU と大容量のシステムメモリ(RAM、128GB 以上が目安)だけでも動作させることは可能ですが、その場合の処理速度は実用的とは言えないレベルになることがあります。
- 用途: より複雑な推論、専門的な分析、高品質なコンテンツ生成など。
- 立ち位置: 将来的な「本格運用の選択肢」。クラウドの商用モデルに匹敵する性能を目指す。
この 2 つの関係は、普通乗用車と F1 カーに例えると分かりやすいかもしれません。20B モデルは、誰もが日常的に運転できる信頼性の高い「普通車」。一方、120B モデルは、最高の性能を出すために専門の設備と技術が必要な「F1 カー」です。 まずは 20B モデルでローカル AI の利便性と安全性を体感し、将来的にさらなる性能が必要になった際に 120B モデルへのステップアップを検討する。`gpt-oss`は、企業の成長段階に合わせて選べる、こうした柔軟性も魅力の一つなのです。
ファインチューニングの誤解:「学習」させても 20B が 120B になるわけではない
ここで一つ、重要な注意点があります。先ほど解説した「ファインチューニング」は、AI に新たな知識を与える「研修」であり、AI の根本的な性能(パラメータ数)を向上させるものではありません。
つまり、20B モデルにどれだけ自社のデータを学習させても、120B モデルのように賢くなるわけではないのです。
これは、AI の「学習」と「推論」の違いに起因します。
- 学習(Training): 大量のデータからパターンを学び、賢さの土台(パラメータ)を構築するプロセス。これには膨大な計算資源と時間が必要です。オープンソース LLM は、この「学習済み」の状態で公開されています。
- 推論(Inference): 学習済みのモデルを使って、私たちの質問に答えたり文章を生成したりすること。私たちがローカル PC で動かすのは、この「推論」の部分です。
- ファインチューニング: 学習済みの推論モデルを、特定の分野のデータセットを使って微調整(追加学習)し、その分野に特化させること。
先ほどの「新入社員」の例で言えば、ファインチューニングはあくまで「自社業務に関する研修」です。研修を重ねることで業務知識は豊富になりますが、その社員の地頭や基礎能力(パラメータ数)が、経験豊富なベテラン社員(120B モデル)と同じレベルになるわけではない、と考えると分かりやすいでしょう。
20B モデルは「優秀な新入社員」、120B モデルは「経験豊富な専門家」。それぞれの特性を理解し、目的に応じて使い分けることが重要です。
【重要】「推論モデル」と「マルチモーダル AI」は違う:AI は“何でも屋”ではない
ここで、特に企業の意思決定層が陥りがちな、もう一つの重要な誤解について触れておかなければなりません。「生成 AI」と聞くと、まるで魔法のように画像も文章も音楽も作り出す「万能な存在」をイメージしてしまうかもしれません。
しかし、この記事で解説している `gpt-oss` のようなオープンソース LLM の多くは、テキストの生成や理解に特化した「推論モデル(テキストモデル)」です。一方で、画像や音声など複数の種類のデータ(モダリティ)を扱える AI を「マルチモーダル AI」と呼びます。両者は得意なことが全く異なります。
項目 | 推論モデル(テキスト特化) | マルチモーダル AI |
|---|---|---|
得意なこと | 文章の作成、要約、翻訳、質疑応答、コード生成 | テキスト、画像、音声、動画などを横断的に理解・生成 |
できないこと | 画像や動画の直接生成、音声認識 | (モデルによるが)特定の専門分野での深い推論はテキスト特化モデルに劣る場合がある |
具体例 | gpt-oss, Llama 3 | GPT-4o, Gemini |
連携の例 | 画像生成 AI(Stable Diffusion など)に与えるプロンプト(指示文)を生成する | このラフスケッチを元に Web サイトのコードを書いて」といった指示を理解する |
つまり、`gpt-oss` を導入しても、それ単体で画像が作れるようになるわけではありません。しかし、「洗練された広告コピーを考え、そのコピーに合う画像のプロンプトを 10 個提案して」といった、テキストベースの高度な連携は非常に得意です。
ローカル AI 活用の第一歩は、この「得意なこと」を見極め、万能性を求めるのではなく、特定の業務に特化させることから始まります。
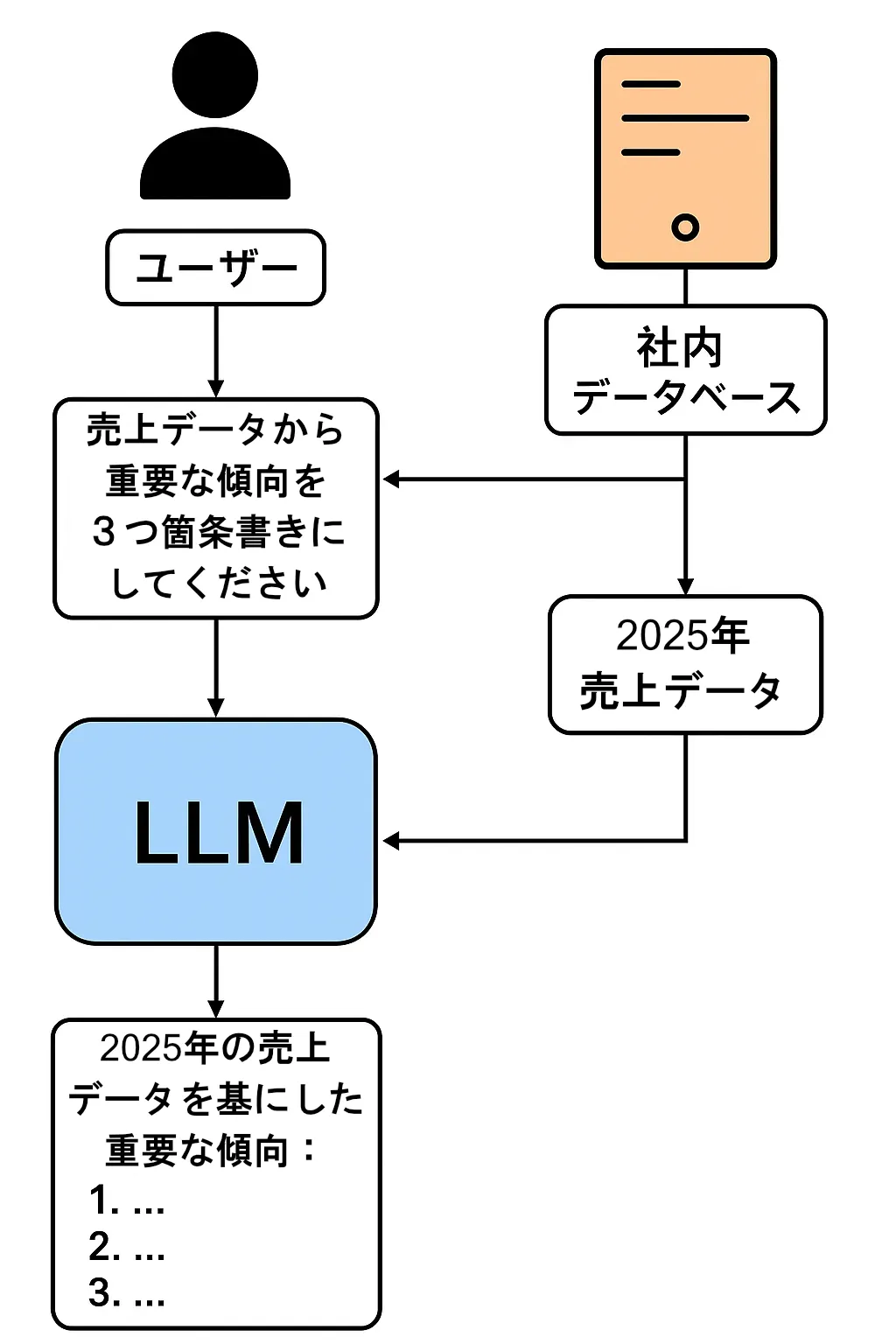
自社特化 AI を育てる二つのアプローチ:ファインチューニングと RAG
AI を自社の業務に特化させる手法として、先ほど「ファインチューニング」を紹介しましたが、実はもう一つ「RAG(ラグ)」という強力なアプローチが存在します。この二つの違いを理解することが、ローカル AI 活用の鍵となります。
アプローチ 1:ファインチューニング(AI の研修)
これは「AI の新入社員研修」に例えられます。専門用語や社内特有の言い回し、応答のトーンなどを追加学習させ、AI の振る舞いや思考のクセそのものを組織の文化に馴染ませるアプローチです。モデル自体を微調整するため、より専門的で自然な応答が可能になりますが、学習にはコストと専門知識が必要です。
アプローチ 2:RAG(AI にカンペを渡す)
RAG とは「Retrieval-Augmented Generation(検索拡張生成)」の略で、「AI にカンペを渡す」アプローチに例えられます。
これは、先ほどの『LLM とは別の「企業の情報(データ)」を充実させることで、LLM が参照できるデータを増やしていく』という考え方そのものです。AI に質問が来た際、まず社内のナレッジベース(マニュアル、議事録など)を検索し、関連性の高い情報を「カンペ」として AI に渡します。AI はそのカンペを参照しながら回答を生成するため、AI 自体の知識は変わらなくても、常に最新かつ正確な社内情報に基づいた回答が可能になります。
比較まとめ:どちらを選ぶべきか?
項目 | ファインチューニング(研修) | RAG(カンペ) |
|---|---|---|
目的 | AI の応答スタイルや思考のクセを組織に最適化する | 最新かつ正確な社内情報に基づいた回答を生成する |
アプローチ | モデル自体を追加学習で微調整する | 外部データベースを検索し、関連情報を AI に与える |
メリット | ・専門用語や社内特有の言い回しに強くなる | ・導入が比較的容易 |
デメリット | ・学習にコストと時間がかかる | ・検索システムの精度が回答の質を左右する |
多くの企業にとって、まず取り組むべきは手軽で効果の高い RAGでしょう。社内ナレッジを整備し、RAG の仕組みを構築するだけで、情報漏洩のリスクなく「社内のことに詳しい AI アシスタント」をすぐに実現できます。その上で、特定の用途で AI の応答スタイル自体を調整したくなった場合に、ファインチューニングを検討するのが現実的なステップと言えます。
【補足】ファインチューニングの結果はどこへ?「新しいモデル」が生まれる
ここで、鋭い方は「ファインチューニングという研修の結果は、一体どこに記録されるのだろう?」という疑問を持つかもしれません。結論から言うと、ファインチューニングを行うと、元のモデルとは別の、新しい「微調整済みモデルファイル」が生成されます。
これは、元のモデル(例:`gpt-oss`の 20B モデル)をコピーし、その上に自社データでの研修結果(微調整されたパラメータ)を上書き保存するイメージです。
- 元のモデル(研修前):『一般教養は完璧な新入社員』のデータ
- ファインチューニング後: 『自社業務研修を終え、専門知識と思考のクセを身につけた新入社員』の新しいデータ
つまり、ファインチューニングは単なる「設定変更」や「プロンプトの工夫」ではありません。AI の頭脳そのものであるモデルファイル自体を、自社専用にカスタマイズした「新しいバージョン」として作り出す行為なのです。
この「新しいモデル」を読み込んで使うことで、初めてファインチューニングされた応答が可能になります。一方、RAG は元のモデルを一切変更せず、外部の情報を都度参照するだけ、という点が大きな違いです。
【Q&A】中小企業でもファインチューニングは現実的?
ここまで解説すると、特に専門の IT 管理者がいない中小企業の方々からは、次のような疑問が聞こえてきそうです。
Q1. 専門家なしで、本当にファインチューニングなんてできるの?
A1. 現状ではまだ少し専門知識が必要ですが、将来的にはもっと手軽になる可能性が高いです。
正直にお伝えすると、2025 年現在、ボタン一つで簡単にファインチューニングができる、という段階にはまだ至っていません。学習用の高品質なデータ(Q&A 集など)を数百〜数千件用意したり、学習を実行するための環境を整えたりするには、ある程度の試行錯誤が必要です。
しかし、`Ollama`のようなツールが LLM の利用を劇的に簡単にしたように、今後はファインチューニングを自動化・簡略化するツールが登場することはほぼ確実でしょう。 ですから、現時点での現実的な戦略は「まずは RAG で成功体験を積み、社内データを整備しながら、次の一手としてファインチューニングの動向を注視する」ことだと言えるでしょう。
Q2. 普通にチャットで使っていれば、勝手に学習してくれるの?
A2. いいえ、ローカル AI はあなたが許可しない限り、勝手に学習することはありません。
これは非常に重要なポイントです。ローカル AI は、クラウドサービスとは異なり、日々の対話内容を自動で学習データとして利用することはありません。 ファインチューニングは、私たちが意図的に「研修モード」を開始し、「この教材(データセット)で学習してください」と明確に指示した場合にのみ実行される、特別なプロセスです。したがって、意図しない情報が勝手に学習されてしまう心配は一切なく、セキュリティ面でも非常に安全です。
Q3. 下手にいじって、元のモデルを壊してしまう危険はないの?
A3. 心配ありません。元のモデルが壊れることは絶対にありません。
これもローカル AI の大きなメリットです。ファインチューニングは、元のモデル(大本の OSS)に直接変更を加えるわけではありません。 先ほどの【補足】で解説した通り、プロセスとしては① 元のモデルをコピーし、② そのコピーに対して追加学習を行い、③ 全く新しい「研修済みモデル」として保存します。
元の「まっさらなモデル」は手付かずのまま残るため、ファインチューニングがうまくいかなくても、いつでも元の状態からやり直すことができます。何度でも失敗できる、非常に安全なプロセスなのです。
現実的な課題と乗り越え方
ローカル AI は多くのメリットをもたらしますが、導入にあたってはいくつかの現実的な課題も存在します。しかし、これらの課題は適切な理解と計画によって乗り越えることが可能です。
① ハードウェア要件:どのくらいのスペックが必要か?
ローカル AI の導入を検討する上で、最も気になるのが「どの程度の PC スペックが必要か」という点でしょう。結論から言えば、`gpt-oss` のような CPU で動作するモデルの登場により、そのハードルは劇的に下がりました。
CPU で動かす場合(最低ライン):
- CPU: 近年のマルチコア CPU(Intel Core i5 / AMD Ryzen 5 以上を推奨)
- メモリ(RAM): 16GB 以上(32GB あれば、より大きなモデルを快適に動かせます)
`gpt-oss` の最大の利点は、高価な GPU がなくても、多くのビジネス PC に搭載されている CPU とメインメモリだけで動作する点です。まずは手元のマシンで「試してみる」ことが可能です。
GPU で高速化する場合(推奨ライン):
- GPU: NVIDIA 製 GPU(VRAM 8GB 以上、16GB 以上が理想)
やはり、快適な応答速度を求めるなら GPU の力は絶大です。特に、ファインチューニングや RAG のためのインデックス作成など、より高度な活用を目指す場合は GPU の導入が視野に入ります。しかし重要なのは、以前のように数十万円の投資が「必須」ではなく、「選択肢」の一つになったという点です。
② 技術的ハードルと運用負荷:誰が面倒を見るのか?
オープンソースである以上、環境の構築やモデルのアップデート、トラブルシューティングなどは自社で行う必要があります。「誰がその役割を担うのか?」は、特に IT 専門の担当者がいない中小企業にとっては大きな課題です。
乗り越え方:
スモールスタート: まずは `Ollama` や `LM Studio` のようなツールを使い、特定の個人の PC で試してみることから始めましょう。これらのツールは導入が非常に簡単で、専門知識がなくてもすぐにローカル AI を体験できます。
外部パートナーの活用: 自社だけで抱え込まず、ローカル AI の構築・運用をサポートしてくれる外部の専門家や IT ベンダーと連携することも有効な選択肢です。初期構築だけを依頼し、運用は自社で行うといった分担も考えられます。
③ モデルの性能:最新の商用モデルとの差
オープンソース LLM の性能は日々向上していますが、現時点では GPT-4o のような最新・最高の商用モデルと比較すると、推論の精度や対応できるタスクの幅で見劣りする場面があるのも事実です。
向き合い方:
用途を限定する: ローカル AI に「何でも屋」を求めるのではなく、「社内規定に関する質問応答」「定型的な報告書の要約」「ソースコードのレビュー補助」など、特定のタスクに特化させて活用することが成功の鍵です。
RAG との組み合わせ: 前述の RAG を活用すれば、モデル自体の知識量に依存せず、社内データに基づいた正確な回答を生成できます。これは、オープンソースモデルの弱点を補い、実用性を高める非常に効果的な方法です。
【提言】ローカル AI 導入、スモールスタートのすすめ
ここまでローカル AI のメリットと課題を見てきましたが、最も重要なのは「完璧な環境を待つのではなく、まず一歩を踏み出すこと」です。 全社一斉に導入しようとすると、予算確保や合意形成、環境構築など、多くのハードルに直面します。そこで私が提言したいのが、「スモールスタート」です。
- 個人で試す: まずは IT に詳しい従業員や、AI 活用に意欲的な従業員が、個人の PC で `Ollama` や `LM Studio` を使ってローカル AI を試してみましょう。費用はかからず、リスクもありません。どのようなことができるのか、どのような課題があるのかを肌で感じることが第一歩です。
- 部署で試す: 次に、特定の部署(例えば、開発部や法務部、カスタマーサポート部など)で、試験的に導入します。用途を「ソースコードのレビュー補助」「契約書のドラフトチェック」「問い合わせ対応のナレッジ検索」など、具体的な業務に限定することで、効果測定がしやすくなります。
- 効果を共有し、横展開する: 試験導入で得られた成功体験やノウハウを社内で共有し、他の部署へと徐々に展開していきます。現場からの「便利だ」「使える」という声が、全社的な AI 活用への最も強力な推進力となるでしょう。
ローカル AI は、もはや専門家だけのものではありません。この手軽さを活かし、小さな成功体験を積み重ねていくことが、自社に合った AI 活用の形を見つける最短ルートなのです。
中小企業が「デジタル資産」を築くための具体的アプローチ
ローカル AI の真価は、単なるコスト削減やセキュリティ対策に留まりません。それは、これまで個人の頭の中やバラバラのファイルに眠っていた「暗黙知」を、検索・再利用可能な「デジタル資産」へと転換するプロセスそのものにあります。ここでは、中小企業がその第一歩を踏み出すための具体的なアプローチを解説します。
なぜ今、デジタル資産化が重要なのか?
- 属人化からの脱却: ベテラン社員の退職と共に失われていた貴重なノウハウや勘所を、組織の知識として継承できます。
- 圧倒的な業務効率化: 「あの資料どこだっけ?」といった情報検索の時間を削減し、本来の業務に集中できます。
- 新たな価値創造の土台: 蓄積されたデータを分析することで、新しいサービスや業務改善のヒントを発見できます。
デジタル資産化への 4 ステップ
Step 1: 情報の「棚卸し」と「一元化」
まずは、社内に散在している情報を一箇所に集めることから始めます。
対象となる情報:
- ドキュメント類: 社内マニュアル、業務手順書、過去の提案書、企画書、議事録
- コミュニケーション記録: 日報、週報、顧客とのメールやチャットの履歴
- 技術情報: 設計図、仕様書、ソースコードのコメント
- 方法:
これらの情報を、特定のファイルサーバーや、Notion、Confluence といった社内 Wiki ツールに集約します。
最初は完璧でなくて構いません。まずは「ここを見れば情報がある」という状態を作ることが目標です。
Step 2: 「構造化」と「フォーマット統一」
次に、集めた情報を AI が理解しやすい形に整えていきます。
- テンプレートの活用: 議事録であれば「日付・参加者・決定事項・ToDo」といった項目を、問い合わせ履歴であれば「顧客名・内容・対応者・解決状況」といった項目を決め、フォーマットを統一します。
- Markdown 形式の推奨: シンプルな記法で構造を表現できる Markdown は、人間にも AI にも分かりやすく、デジタル資産の記述形式として非常に優れています。今ご覧の記事も Markdown で書かれています。 この地道な作業が、後の検索精度を大きく左右します。
Step 3: RAG による「生きたナレッジベース」の構築
情報が整理できたら、いよいよ AI の出番です。
- RAG の導入: 前述の RAG(検索拡張生成)の仕組みを導入し、一元化・構造化されたデータを参照させます。
- 効果: これにより、従業員は「〇〇社の去年の提案書を見せて」「製品 B のトラブルシューティング手順を教えて」といった自然な言葉で、必要な情報へ瞬時にアクセスできるようになります。情報は「ただ保管されている」状態から、「いつでも呼び出せる生きた知識」へと変わります。
Step 4: ファインチューニングによる「専門家 AI」への昇華
RAG の運用を通じて高品質な Q&A データが蓄積されてきたら、次のステップとしてファインチューニングを検討します。
目的特化: 「見積もり作成の補助」「技術的な問い合わせへの一次回答」「新人研修用の対話シミュレーター」など、特定の業務に特化した AI を育成します。
効果: RAG が「優秀な検索アシスタント」だとすれば、ファインチューニングは組織の文化や思考のクセまで理解した「頼れる専門家」を育てるプロセスです。
重要な心構え:完璧より、まず始める
この 4 ステップは壮大に見えるかもしれませんが、最も重要なのは「完璧を目指さず、まず始めること」です。日々の業務の中で、少しずつ情報を整理し、テンプレートを一つ作ってみる。その小さな積み重ねが、数ヶ月後、数年後には、他社には真似できない強力な「デジタル資産」となっているはずです。
まとめ:ローカル AI は「守り」と「攻め」を両立する DX 戦略
従業員の無断利用による「シャドー AI」のリスクは、多くの企業にとって喫緊の課題です。しかし、その背景には「AI を使って業務を効率化したい」という現場の前向きなニーズがあります。
`gpt-oss` に代表されるローカル AI は、この課題に対する完璧な答えとなり得ます。機密情報を外部に出すことなく、絶対的なセキュリティを確保する「守り」の策であると同時に、社内ナレッジを最大限に活用し、自社だけの「お抱え専門家」を育成することで、新たな競争力を生み出す「攻め」の DX 戦略でもあるのです。
リスクを恐れて AI という強力な武器を遠ざける時代は終わりました。自社の管理下で賢く使いこなし、ビジネスを加速させる。ローカル AI は、そんな新しい時代の扉を開く鍵となるでしょう。